Mockless Testing
So we've pretty much done this project isolated from home, often discussing how we should write our backend services in an endless echo chamber of positive reinforcement. Which is great. No one to rain on our parade of insanity.
Our increasingly deluded minds have concluded that when it comes to deploying our micro-services Mocks, Stubs, Fakes and Spies ruin everything.
No really. Hear us out. (Or you could just go and check out our github example here)
But first, we need to get to the point where that’s an issue. So let’s start with the small topic we call testing.
Testing
As naming convention, we’ve decided to borrow from Uncle bob:
Micro-test: A term coined by Mike Hill (@GeePawHill). A unit test written at a very small scope. The purpose is to test a single function, or small grouping of functions.
Functional Test: A unit test written at a larger scope, with appropriate mocks for slow components.
Unit Test: A test written by a programmer for the purpose of ensuring that the production code does what the programmer expects it to do.
Testing is a hot topic which you can’t just find the right answer to on the internet. People disagree. Experts disagree. You’ll find a data scientist who thinks unit tests are a waste of time and should just be skipped altogether, some other architect who is happy with waiting 15 minutes for test results from their jenkins servers instead, and then Robert C. Martin (Uncle Bob), who will just say that you’ve designed your code wrong if it’s hard to test and mock and speed is vital. Integration tests, System tests, Functional tests, Micro tests…
Apparently, testing is controversial. So here’s our take. Start with the business value. Start with a functional test and go from there.
As a backend developer, when we start with a user story, the first question we ask is often, what is the expected behavior of our service. Often, we agree on an interface for the consumers (often represented as endpoints) and that’s our entry point.
So if we want to start with writing a test, that’s where we should start right? A functional test.
This of course doesn’t mean that we’re saying functional tests are the only thing that should be written. Complex business logic is still very nice to do in micro tests for example. But right now, there is no logic to test. No point in writing a bunch of business logic that can’t even be invoked yet.
So let’s say we have a user story that is about creating customers through a rest endpoint.
For this example, a functional test would mean calling our service through this endpoint and evaluate the result. That’s easy these days. Java frameworks like Spring and Quarkus give us the possibility to annotate a test class, which in turn will start up our little micro-service with an endpoint to invoke. Then there are great test libraries like RestAssured that make tests easy to read.
We start writing a test and it looks like this.
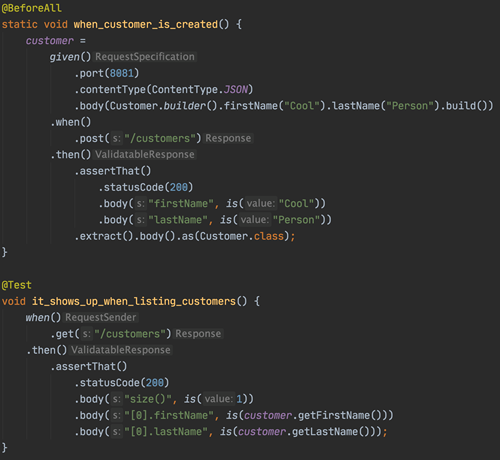
Great! We have a test. Lets get it green! We start writing our code. Which, we discover, requires a lot of external dependencies towards a lot of different things. We store our data in a database, we do requests towards other services, send some stuff out on Kafka topics, listen and react to other topics.
One solution for this would be to mock away the HTTP/Kafka communication, database queries, add mock functionality in the test, and run it.
But. How much can we trust a test with mocks? What are we testing? And what did we leave behind? What about our nice queries towards our database? Not tested. Instead of relying on our tests while developing, we often start running it on our local machines and our “test driven” development is now manual. We do not treat those tests as first class citizens.
After all, with today’s frameworks, the vast majority of the code that is run in our micro-service is not written by us. A lot of it is driven by annotations and property files. How do we verify that we’ve set it up properly?
So we decided to go all out. No mocks!
Luckily, there were no sane backenders involved in this project, so no one could object.
Method
Below we are mainly focusing on the database and external service communication. Corresponding code is gathered in the github repository accompanying this post.
We also have an example set up with kafka, which we’ll just briefly mention. You can find it in a side branch here.
Database
In our project, we use PostgreSQL. If we don’t want to mock, there are solutions like in-memory databases. Great, right? Nope! We said the real thing! We want to be able to do PostgreSQL specific things because that’s what our code does. Why would we use PostgreSQL otherwise?
There are two ways to get what we want for that. First option is to use test containers:
https://www.testcontainers.org/
The other option is to just embed it with our tests, which is what we went for. Luckily there are projects out there that can help us easily achieve this:
https://github.com/zonkyio/embedded-postgres
Alright! We have our embedded Postgres server running with our tests! Lets run it!
Oh.. we’re still missing our schema. And their tables. Sure, we could add an sql-script that gets added before we run our tests to give us a mirror image of our production. But we can’t really trust that now can we? That’s not a true reflection of our environment. It’s just a snapshot of it. If someone updates the db, they better remember to update our test scripts! That’s not good. We must be able to trust our tests.
So how do we make sure that we can trust our tests when our micro-service connects to a database out of our control?
Well that’s the problem, isn’t it. The solution is to simply decide that our micro-service owns the data in the database. It should be the owner of the tables and whatever triggers and other scripts that run on them. The only way to change the database should be to deploy a new version of our micro-service.
How do we do that?
Database Migration
We use a database migration tool called Flyway by Redgate. Flyway creates a table in our schema that simply holds the information of which script files it has run. So if we run Flyway and point towards a folder with sql-scripts. It will look at the file names and compare it to the db. Flyway will then run all scripts that have a higher version name. As an example, the migration folder could have a list of files looking like this:
V1.1__Create_basic_tables.sql
V1.2__Update_customer_with_new_column.sql
V2.0__Create_order_flow_tables.sql
Where, if flyway would be on V1.2, it would run all files with a name corresponding to V1.2.1+, which in this case would be the V2.0 file.
When we start our service, it will connect to the database and run flyway. From our example above, V2.0__Create_order_flow_tables.sql will be executed. And that’s pretty much how flyway works. A more detailed explanation can be found here:
https://flywaydb.org/documentation/getstarted/why
So now our micro-service is the full fledged owner of our data. The great side effect of this is that we can now run our tests, and we can be sure that we invoke the same tables with the same database functions and triggers that the production has. We can actually test our sql scripts with just our usual tests! Row Level Security? It is tested with a regular functional test. Trigger to modify a field on insert? Your test can verify that. And the test is not even aware that it’s testing the sql functionality! It still just tests incoming and outgoing data.
So, now we’ve solved the database. What’s next?
External services
When calling other services via http(s) we can’t really get away from the fact that whatever service we call is something we do not control. What we can control though is that we fulfill the contract or specification that has been given to us. In order to not have to mock away our rest client, we solve this with Service Virtualization. It’s described a bit more in detail here
Just like in the video, we use Hoverfly. Hoverfly is essentially a man-in-the-middle proxy server that can either pass through messages back and forth while recording them or evaluate the requests, and then, if it has a match for that request, send back a response.
Hoverfly has a support library for JUnit in Java which, when activated, starts a Hoverfly proxy server and sets this proxy for all http clients in our service. Hoverfly also provides a tool for defining what responses will be returned for each request through a Domain Specific Language.

While we will now have to add some code to our test, the test is still only specifying incoming and outgoing data.
And also, we can still make our tests follow a pattern of given-when-then by isolating our DSL away in a representation class for each external service that builds the DSL for us so our tests can look a bit nicer like this.
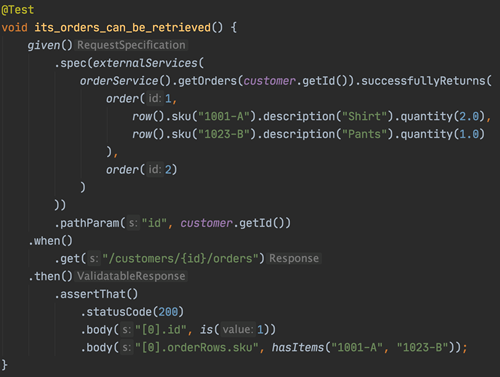
You might ask what we’re really gaining here and argue that we’ve just done a more complicated version of mocking away a rest client in our service. But when using a framework like Quarkus or Spring, a rest client connecting external services is defined with interfaces, annotations and configuration properties. The rest is generated by the framework. If we mock that away, how do we know that we’ve set it up properly? How does the next person know that they don’t break anything when changing an annotation? As we said before, we want our tests to run the same code we run in production.
Kafka
When it comes to Kafka, just like with the database, you can either go with embedded or test containers. Once again we went with embedded using this library:
https://github.com/opentable/otj-kafka
We’re not going to go into details about that part but some things we did notice with our embedded Kafka in particular is that spinning up our tests takes substantially longer. In our simple example, it ends up with an additional 15 seconds in startup which is not great. It’s also not super easy to find nice patterns with asynchronous parts in the tests. As we mentioned earlier, we set up a super simple example in a side branch if you want to see how it’s set up.
Conclusion
Pros
- We always start writing our tests from a functional perspective. What comes in and what goes out of our service.
- When a test passes we trust that we are using external dependencies correctly, even native database functionality.
- We deploy tested database changes together with our micro-service
- We can test every scenario our micro-service needs, production data can be copied, Hoverfly responses from external services can be recorded.
- Our micro-services have all the main flows represented in tests that would only need to be edited if the actual functionality changes. Alternative flows are divided between functional tests and micro tests.
- We feel secure that everything works every time we merge a pull request to master
Cons
- We are still trying to find our way with embedded Kafka, it takes a few moments to start up. A sane person might come in one day and ask why we’re even doing it but until then, we’ll keep trying.
- Running a single functional test can be a bit annoying if you’re changing small things continuously. To run a test that starts up a Quarkus service together with an embedded database, Hoverfly proxy, etc takes around 20 seconds.
- Having a lot of functional tests takes more time than just running micro tests. Our biggest microservice so far has embedded Postgres, Hoverfly, Kafka, gRPC and around 200 functional tests and the total test time with startup included is around 45-50 seconds. Out of those, startup is around 30 with Kafka as the biggest culprit.