Web scraping with PuppeteerJS

Web scraping and how to do it with PuppeterJS.
If you're a web developer, you've probably heard of web scraping – the art of extracting information from websites. It involves making HTTP requests to a website and parsing the HTML or other structured data that is returned in the response. The extracted data can then be used for various purposes, such as data analysis, machine learning, or creating new applications. It's a useful skill to have in your toolkit, but let's face it: web scraping can be a bit of a hassle. That's where PuppeteerJS comes in.
PuppeteerJS is a powerful library that allows you to control a headless Chrome instance, simulating a user's actions on a website. This means you can easily scrape data from any website, without having to worry about all the complexities of HTTP requests and HTML parsing.
To illustrate how easy it is to use PuppeteerJS for web scraping, let's go through a simple example. Imagine you want to scrape the titles of the latest podcast episodes on “Darknet Diaries” Here's how you would do it with PuppeteerJS:
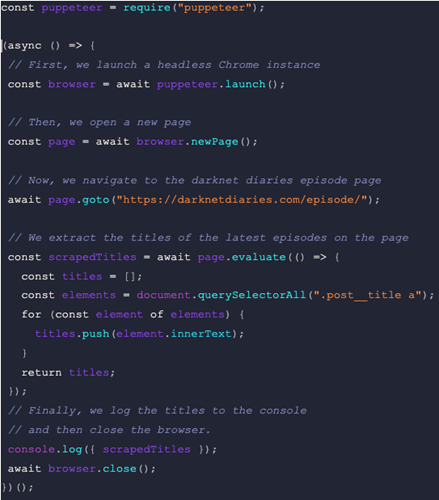
And that's it! With just a few lines of code, you've managed to scrape the titles of the latest episodes of “Darknet Diaries”. PuppeteerJS makes it incredibly easy to extract information from websites, and the sky's the limit when it comes to what you can do with it.
Is Puppeteer my only option if I want to start web scraping?
There are other alternatives to PuppeteerJS for web scraping. Some popular options include:
- Request: Request is a widely-used library for making HTTP requests in Node.js. It provides a simple API for sending requests and receiving responses, and it is often used as the foundation for building web scraping tools. Request is a good option if you only need to scrape websites that provide data in a structured format, such as JSON or XML.
- Cheerio: Cheerio is a library that parses HTML and provides an API for traversing and manipulating the resulting data structure. It is often used in conjunction with Request to scrape websites that provide data in an HTML format. Cheerio is a good choice if you are comfortable working with HTML and want to extract specific elements from a web page.
- Selenium: Selenium is a suite of tools for automating web browsers. It provides a high-level API that allows you to write scripts to control a browser and interact with websites. Selenium is a good option if you want to scrape websites that use complex interactions or require authentication.
Each of these alternatives has its own strengths and weaknesses, and the best choice will depend on your specific needs. For example, Request is a lightweight and easy-to-use library, but it may not be suitable for scraping websites that use dynamic content. On the other hand, Selenium provides a comprehensive set of tools for automating web browsers, but it may be more difficult to set up and use.
So why bother with PuppeteerJS over other alternatives?
There are several reasons why you might choose to use PuppeteerJS for web scraping, even though there are other alternatives available.
Here are a few reasons:
- PuppeteerJS is built on top of the Chromium project, which means you can use it to control a real browser and interact with websites exactly as a user would. This is useful because many websites use dynamic content that is generated using JavaScript, and traditional web scraping tools may not be able to extract this data.
- PuppeteerJS provides a high-level API that makes it easy to write scripts to control a headless Chrome instance. You can use this API to automate common tasks, such as filling out forms, clicking buttons, and extracting information from web pages.
- PuppeteerJS allows you to run your web scraping scripts in a serverless environment, such as AWS Lambda or Google Cloud Functions. This means you can scale your web scraping operation to handle large volumes of data without worrying about managing servers.
Overall, PuppeteerJS is a powerful and versatile tool that can be used for web scraping, and it is worth considering if you need to extract information from websites that use dynamic content. But it does have some limitations and potential drawbacks that you should be aware of.
- PuppeteerJS uses a headless Chrome instance, which means it requires a significant amount of memory and CPU resources. This may make it difficult to run multiple instances of PuppeteerJS on a single machine, and it may not be suitable for scraping large volumes of data.
- PuppeteerJS is built on top of the Chromium project, which means it is subject to the same limitations and bugs as Chrome. This can cause issues if you are trying to scrape websites that use features that are not supported by Chromium, or if you encounter bugs in the Chromium code.
- PuppeteerJS is a relatively new project, and it is still undergoing rapid development. This can lead to breaking changes in the API and other unexpected issues. As a result, you may need to regularly update your code to keep up with the latest changes.
Overall, PuppeteerJS is a valuable tool for web scraping, but you should be aware of its limitations and potential drawbacks. It may not be the right choice for every situation, and you may need to consider other alternatives depending on your specific needs.
How do I get started with web scraping with PuppeteerJS then?
To get started with web scraping using PuppeteerJS, you will first need to install Node.js on your computer. Then, you can use the npm package manager to install PuppeteerJS with the following command:

Once Puppeteer is installed, you can create a new JavaScript file and import Puppeteer using the following code:

Next, you can use the puppeteer.launch() method to launch a new instance of Google Chrome and create a new page:

Now that you have a page, you can use the page.goto() method to navigate to a specific URL, and the page.evaluate() method to run some JavaScript on the page and extract the data you need. A good tip could be to think of the evaluate() function as the console in the web browser, everything you can type out there can also be done in the evaluate(). For example, you could use the following code to navigate to a website and scrape the text of all the h1 elements on the page:
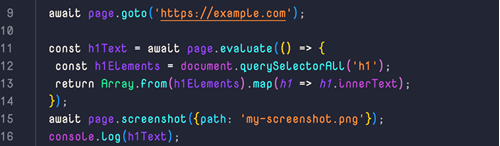
Maybe you want to take a screenshot of the webpage? Well you can easily do that with just adding this line of code:

After you have extracted the data you need, you can close the browser instance using the browser.close() method.

That's just a brief overview of how to get started with web scraping using PuppeteerJS. For more information, you can check out the official PuppeteerJS documentation here.
The full code example should look like this:
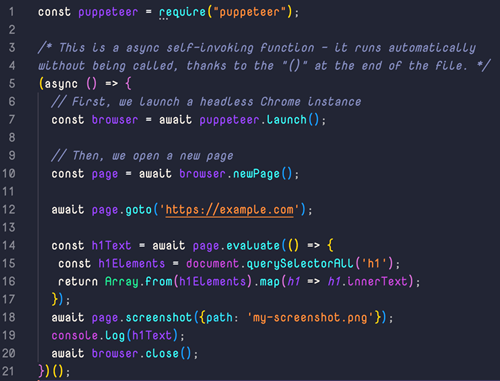
And with that, you're now a puppeteer master. Just remember, if it's on the web, you can scrape it – no strings attached (pun intended).
Oh, and remember, with great power comes great responsibility – so don't use your new skills to spam websites or steal sensitive data! …Happy scraping!