Träna en Machine Learning modell med AWS SageMaker
Det är ofta mycket prat om Cloud och nu på senaste tid har man pratat allt mer om Machine Learning (ML) idag tänkte jag visa ett sätt som AWS erbjuder för att kombinera dem. Vi kommer specifikt titta på Amazon SageMaker Studio för att sätta upp en Notebook som kan träna upp en modell åt oss.
Amazon SageMaker Studio är en IDE för ML som erbjuder ett fullt managerat Jupyter notebook interface där man kan skapa och utforska dataset, förbereda träningsdata, bygga, träna och finjustera modeller och distribuera modeller.
För att kunna använda SageMaker Studio så behöver vi sätta upp en VPC. Exempelvis kan vi sätta upp ett genom att följa: https://docs.aws.amazon.com/vpc/latest/userguide/vpc-example-dev-test.html. Efter den är skapad så kan vi sätta upp en AWS stack och en AWS användare. För den här genomgången räcker det med att vi använder en av AWS exempelstackar så låt oss skapa den med hjälp av följande AWS Quick Stack. Exempelstacken sätter upp en studio-user användare och ett SageMaker Studio domän. Tänk på att man måste kryssa i "I acknowledge that AWS CloudFormation might create IAM resources with custom names". När stacken väl skapats kan vi nu öppna upp SageMakerStudio genom att söka efter det i konsollens sökfält. Dubbelkolla att du är på rätt region och välj sedan att starta SageMaker Studio med studio-user som skapades när vi skapade stacken.
Om allt har gått som det ska så har vi nu lyckats öppna SageMakerStudio och är redo att lägga in vår träningsdata. Detta gör vi genom att lägga till en ny Notebook och när vi väljer vilken miljö vår Notebook ska köra i så väljer vi Data Science som vår image och ml-t3-medium som vår instans typ.
Som första del i vår Notebook behöver vi importera SageMaker biblioteket så importera det med hjälp av pip:

Efter det kan vi importera specifika versioner av så väl XGBoost som Pandas:

Sedan behöver vi instansiera S3 klient objektet och platser i vår default S3 bucket som saker ska sparas till, så som metrics och modelartefakter:
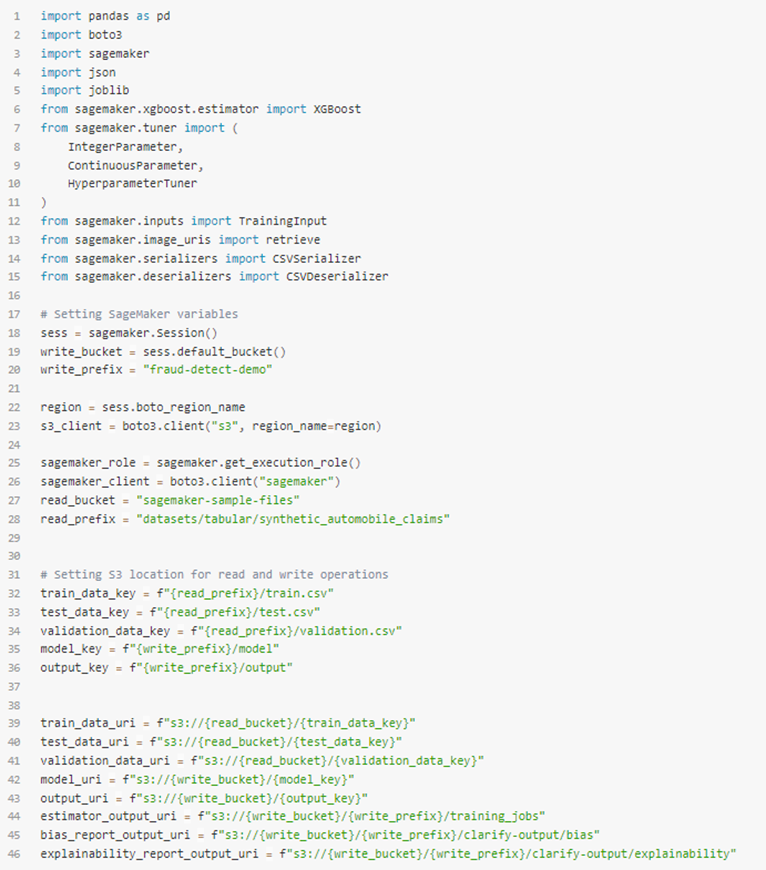
I just det här exemplet kommer jag visa hur vi kan använda en exempelmodel av försäkringsärenden.
Till sist behöver vi sätta upp lite konfiguration för själva träningen:
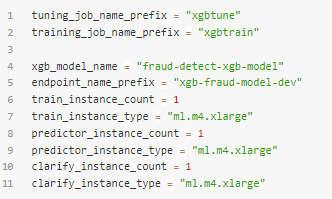
Med detta på plats så kan vi nu lägga till vår egen logik till själva träningen genom följande:
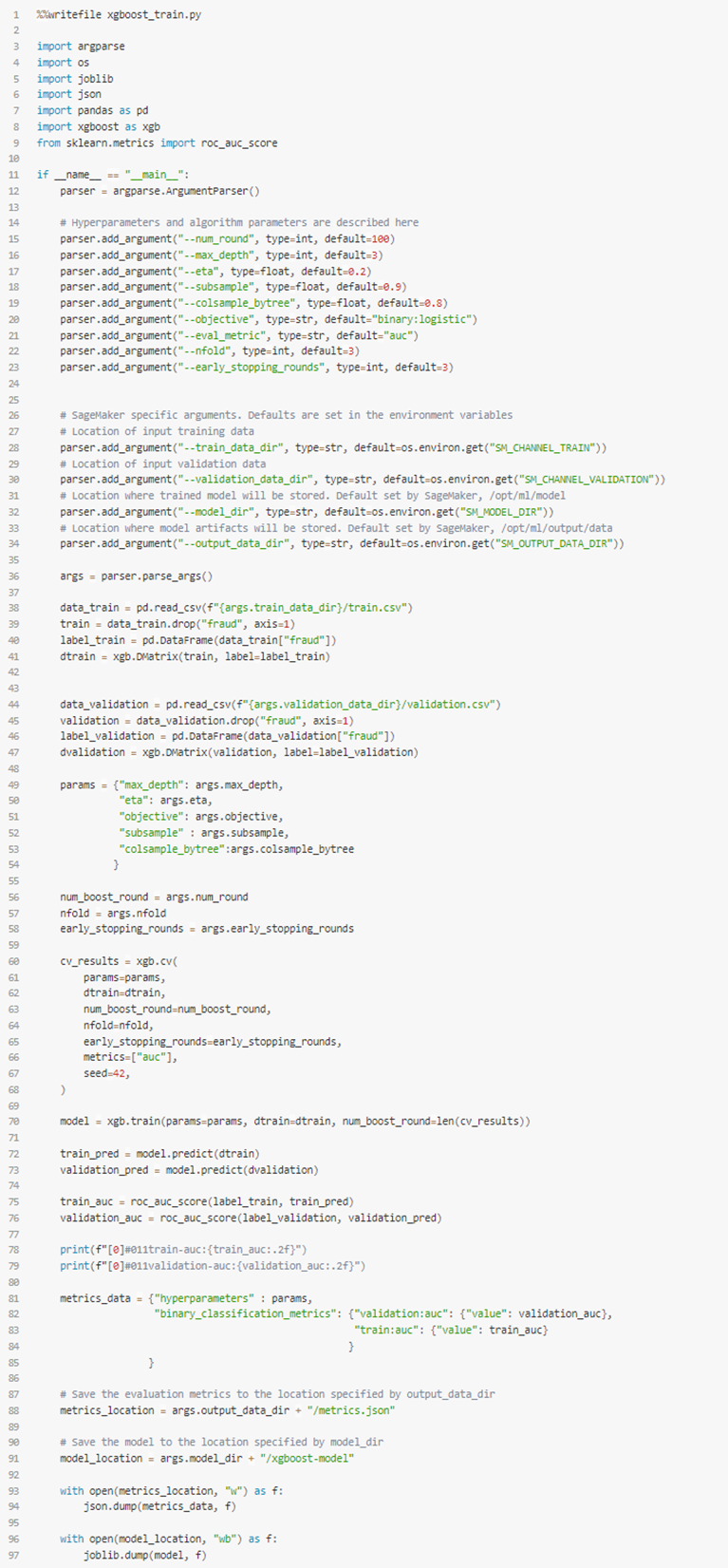
Detta träningsscript kommer sedan köras i en Docker container och kommer hämta den data som behövs från de S3 buckets vi pekade ut tidigare.
För att faktiskt köra det i träningen behöver vi peka ut den fil som skapats. Detta gör vi genom att instansiera en SageMaker estimator genom följande:

Vi kan sedan ställa in några XGBoost hyperparametrar, exempelvis eta, subsample, colsample_bytree och max_depth.
För att sätta upp dessa behöver vi något som såhär:

Vi behöver nu koppla in detta till en "Hyperparameter tuner" på följande sätt:

Nu behöver vi bara köra fit():

och när väl tunern är klar:

Med allt det på plats har vi nu fått fram en ML modell.
Nu när vi äntligen har fått fram en modell kan vi använda den i exempelvis SageMaker Clarify för att hitta fördomar och även låta SageMaker förklara vår modell.
Men viktigast av allt: Vi kan deploya den med hjälp av SageMaker SDK. Men det, det pratar vi om en annan gång!
God Jul!